如何使用隐马尔可夫模型(HMM)进行中文分词?我要来一次自问自答,深入浅出、形象地说明如何使用隐马尔可夫模型进行中文分词。

jerkzhang
要说隐马尔可夫模型(Hidden Markov Model,简称HMM),那还是从马尔科夫模型(Markov Model)来说。备注:马尔科夫模型是前苏联数学家马尔科夫提出的,而隐马尔可夫模型则是Leonard E. Baum等人在20世纪60年代提出的。
先说马尔科夫模型吧:讲个故事吧,以七龙珠为例,神龙现在改变玩法了,神龙决定每隔1小时,吐出一颗龙珠,这颗龙珠,可能是一星龙珠、二星龙珠、三星龙珠……六星龙珠、七星龙珠中的某一种;若能猜中是几星龙珠,神龙就亲你一口!马尔科夫模型就是根据历史数据建模,然后预测未来。
大家都认为每次出几星龙珠,与之前出的那些龙珠类型有关;换而言之,第t次出啥龙珠,与第1次到第t-1次出的龙珠类型都有关系;而马尔科夫模型则将这些简化成,第t此出啥龙珠,只与第t-1次有关系。为啥可以这样简化,因为t-1次出的龙珠就已经与t-2次出的龙珠有关系。简化后成的马尔科夫链就就如下所示:

而通过历史数据的统计就可以知道每一种龙珠后面是另外一种龙珠的概率是多少,1星龙珠后面是1星龙珠的概率XXX、是2星龙珠的概率是XXX...是7星龙珠的概率是XXX;然后看2星龙珠后面是1星龙珠的概率XXX、是2星龙珠的概率是XXX...是7星龙珠的概率是XXX;依次类推3星、4星、5星、6星、7星龙珠后面是各种龙珠的概率。最终统计得到一个7*7的概率矩阵,这就是状态转移矩阵。通过这样的一个方式来预测未来。(上面说的未必严谨,大致主要想用形象的语言表达一下内涵;大致感觉一下即可,这里不对马尔科夫进行实例展开。)
备注:别的相关文档中经常提到的状态,就第几次是哪种的类型的龙珠,几星龙珠就是状态;形成的这条链,就是状态序列。模型如此,具体用这个模型干啥,那就自由搞呗~
马尔科夫模型常用于天气预报、词性自动标注、语音识别等等。
而隐马尔可夫模型呢?
同样以上面的七龙珠例子来说,人们觉得神龙吐龙珠这事是有一个未知的隐藏肌理的,于是就有人推测,神龙分泌龙珠是跟神龙的胃有关系,而神龙是有3个胃的,每个胃产生龙珠种类的概率是不一样的;其实就是,吐出啥龙珠,这是一个表面被看见的序列,俗称观察输出序列;而具体每一次是用哪一个胃来分泌吐出龙珠的,这则是隐含的状态序列,简称隐状态序列;而建模则如下所示:
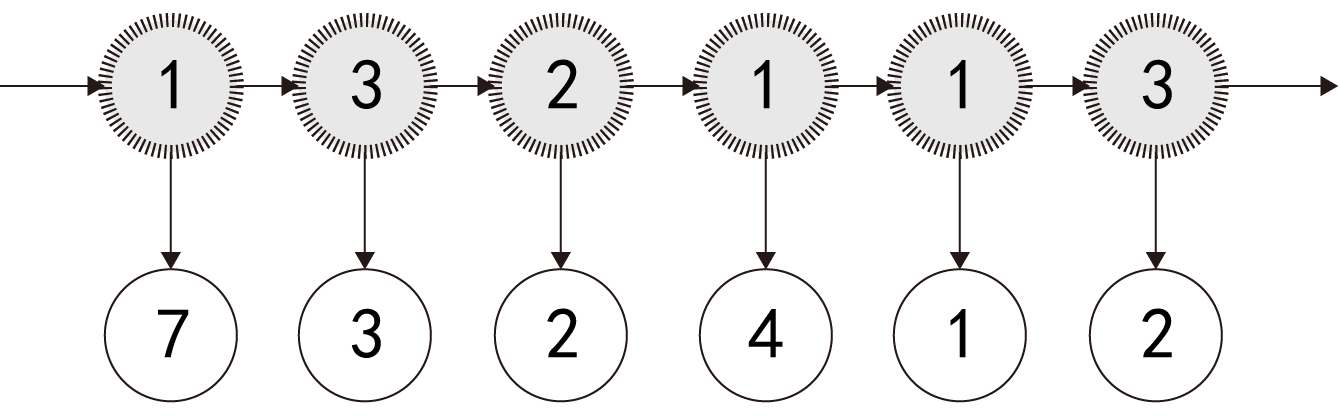
这就是典型的隐马尔可夫模型。要注意,状态转移的关注点不再是上一次是吐出的是几星龙珠,而是上一次是由神龙的哪一个胃来吐出龙珠。
神龙一共几个胃,每次使用哪个胃吐出龙珠,使用胃这件事上的状态转移矩阵是什么样,比如3个胃,那状态转移矩阵就是3*3;另外,不同类型的神龙胃吐出的各类龙珠的概率是怎样的。
隐马尔可夫模型非常强大,可以用于中文分词、股票预测、语音识别等等。
那如何使用隐马尔可夫模型进行中文分词呢?
我们还是以神龙吐龙珠为引,只是每次神龙吐出的不是龙珠,而是1个汉字。而为了要实现中文分词,我们假设神龙有4个胃,分别是Begin胃(简称B)、Middle胃(简称M)、End胃(简称E)、Single胃(简称S),而内在的含义则是:
B,代表这个汉字是一个词语开头的第一字;
M,代表这个汉字是一个词语中间的某个字;
E,代表这个汉字是一个词语末尾的最后一个字;
S,代表这个词语其实就是单独的一个字。
而所谓中文分词,就是把一个句子切割成不同的词语或字(姑且把单字看做只有一个字的词语)。
因此,就是知道了观察输出序列,以隐马尔可夫模型,来推倒出每个汉字对应的是哪类神龙胃(B/M/E/S),其实就是隐状态序列;当知道了由BMES构成的隐状态序列,那不就知道了该如何分词了呗~
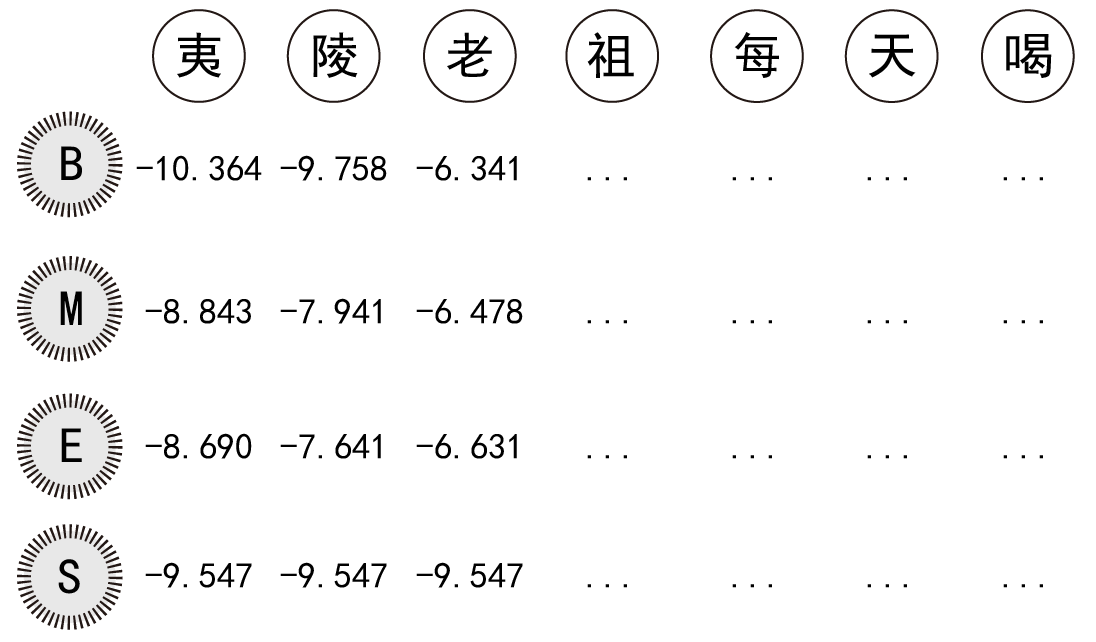
示例句子是:夷陵老祖每天都喝一杯红茶 根据隐马尔可夫模型得出隐状态序列 隐状态序列:BEBEBMESBEBE 根据隐状态序列对句子进行分词: 夷陵 / 老祖 / 每天都 / 喝 / 一杯 / 红茶
隐马尔可夫模型截取部分如下图所示(备注:为啥“每天都”没有被分成“每天”和“都”,这由用于训练模型的语料库有关,暂时不用太在意;单纯的隐马尔可夫本身就是难以做到100%的尽善尽美):
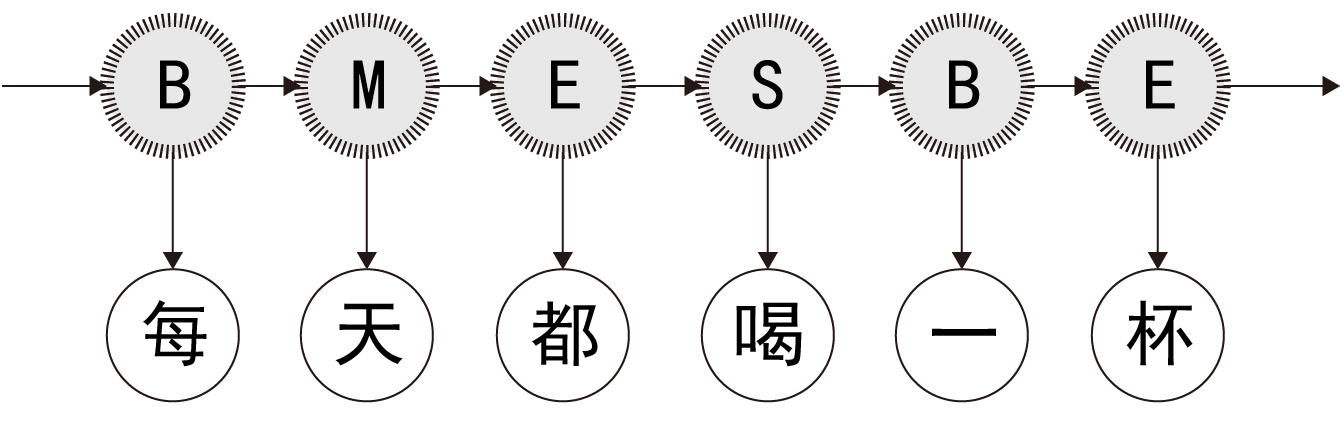
要想使用隐马尔可夫模型进行中文分词,得先通过语料统计得出这个隐马尔可夫模型的一些构成:
1、初始状态概率
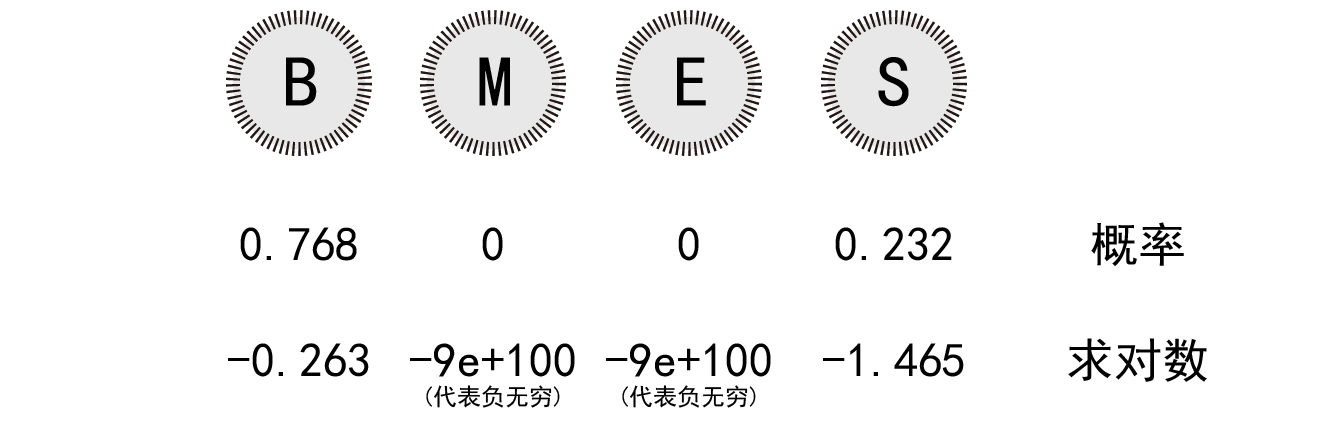
隐马尔可夫中的状态都是针对隐性的状态而言,即神龙的胃是哪一种胃,是专门分泌词语第一个字的胃,还是专门分泌词语结尾字的胃。初始状态概率,就是句子第一个字是来自于神龙的哪个胃的概率。经统计训练得出下方结果,可以直接拿去用:
cmatri = { 'B': 0.768, 'M': 0, 'E': 0, 'S': 0.232 }
用图标表示即:
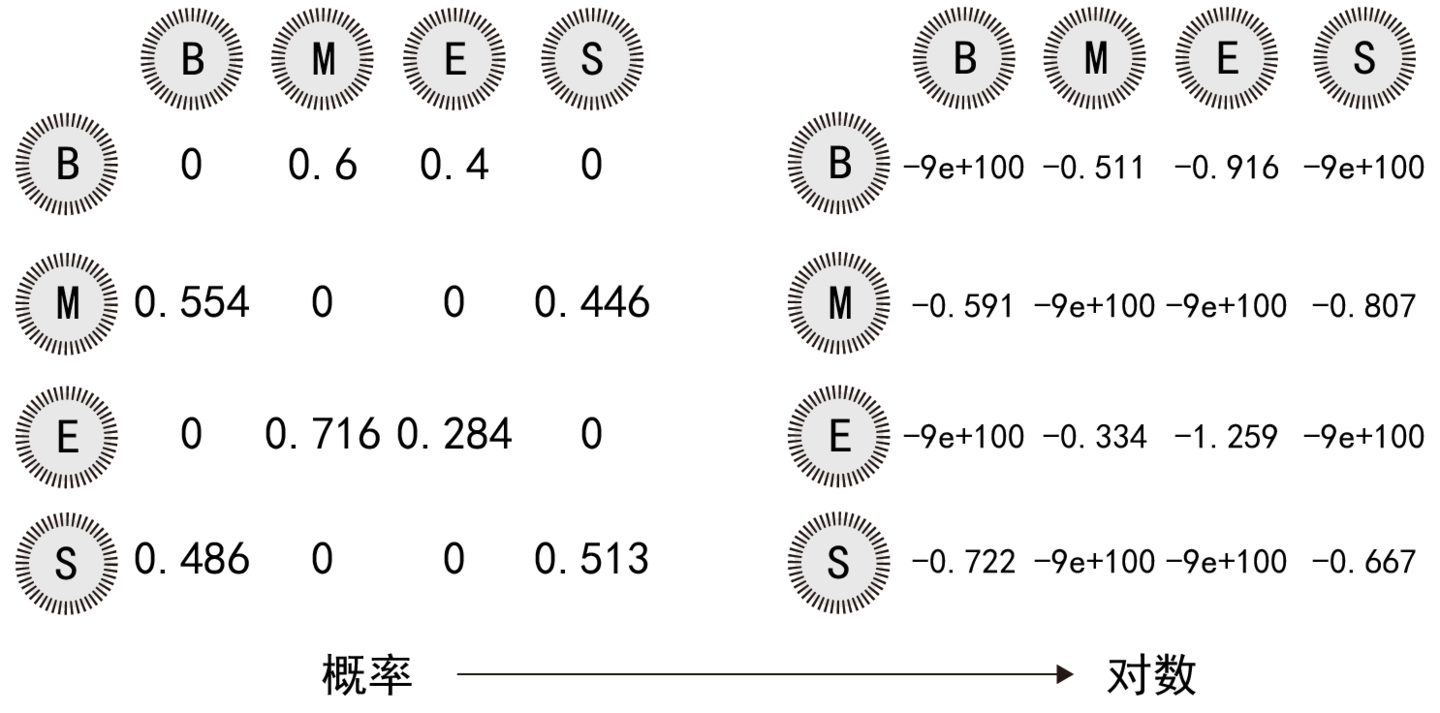
2、状态转移矩阵
前一个字来源于某个神龙的胃的条件情况下,那么当前这个字来源于神龙某个胃的概率。这里就有点类似马尔科夫模型中,t时刻的状态,由t-1时刻的状态决定,只是马尔科夫模型中的状态指的是具体是哪个汉字,而隐马尔可夫模型中的状态是指分泌汉字的神龙胃的编号。
tmatri = { "B" : { "B": 0, "E": 0.6, "M": 0.4, "S": 0 }, \
"E" : { "B": 0.554, "E": 0, "M": 0, "S": 0.446 }, \
"M" : { "B": 0, "E": 0.716, "M": 0.284, "S": 0 }, \
"S" : { "B": 0.486, "E": 0, "M": 0, "S": 0.513 } }
用图标表示如下:
3、观测概率矩阵(即每个神龙胃中分泌出各个汉字的概率)
备注:下图中的数字是根据概率求出的对数,概率的小数点后数字太长了,就不列举了。
思考一下:为啥要用对数而不直接使用代表概率的小数?一是减少数据的偶然性误差(这点我不确定,有人说过),二是将乘法改为加法(这点我很肯定)。
使用代表概率的小数求对数,python代码例如:
>>> import math >>> math.log( 0.554 ) -0.5905905922348531
现在已经有了弄好的隐马尔可夫模型,就可以开始根据模型来预测某段中文句子对应的“BMES”这类隐状态序列是啥。

首先在不考虑算法复杂度的情况下,其实很简单,把所有可能枚举一遍,整体概率最大的那一种方案就是结果。(因为上面根据概率取对数了,所以就不用概率相乘了,而是根据概率得出的那个对数相加即可,整体的和最大的那个就是概率最大的。)
但是枚举是不可取的,因为枚举的算法复杂度太高,得不偿失。
这时候就可以使用动态规划算法了,其中一种动态规划算法叫维特比算法(Viterbi)。此时不仅感慨光阴荏苒,遥想十六年前的我是一个瘦子;可是现在的我已经成为了一个胖子……
以“夷陵老祖每天喝一杯红茶”为例:从最后一个字“茶”为例,“茶”有4种可能;而“茶”之前各字的取值,没必要全部枚举组合一遍,只要与之前“红”这个字分别是B/M/E/S的最大概率时的取值进行组合对比即可,即4*4次对比即可,取出最大可能性即可。
同理对于“茶”而言,也不要对之前的字全部枚举组合比较;只要对比前一个字“杯”取值“B/M/E/S”时分别的最大概率方案即可。依次类推进行递归回溯即可。
不过递归容易栈溢出,也并不够高效,以及维特比算法并不复杂,可以考虑直接使用循环来正向实现,思路还是同样的思路。
备注:对于这个问题,千万要放弃枚举这个念头,比如n个字构成的句子,枚举要算4^n,n一旦比较大,这会是一个天文数字;而使用动态规划算法中的维特比算法,大约算n*4*4即可。
注意临界问题,第一个汉字要么是B或S,最后一个汉字要么是E或S。若使用循环正向进行维特比算法,当到达最后一个汉字时,看倒数第二个汉字即可,倒数第二个汉字是E或S时,最后一个汉字就是S;倒数第二个汉字是M或B,最后一个汉字就是E。
另外初始化使用初始状态概率即可;而之后都是属于有前一个字,根据前一个字使用状态转移矩阵。
初始状态矩阵和状态转移矩阵的训练,我偷懒用的是别人训练好的;关于观测概率矩阵,我分别用了两套语料库,一个是几十万级别,一个是八百万级别,效果都还马马虎虎:
u"夷陵老祖每天都喝一杯红茶" BEBEBMESBEBE 夷陵 / 老祖 / 每天都 / 喝 / 一杯 / 红茶 u"上次我在淘宝看了几件快递员专用的大衣" BMMEBEBEBEBMEBMEBE 上次我在 / 淘宝 / 看了 / 几件 / 快递员 / 专用的 / 大衣 u"立法是一个系统且专业的事情个人认为未成年人保护法已经过时了有修订的必要否则会阻碍社会治安工作也不利于保护更广大的未成年人" BMEBEBESBMMEBMEBEBMMEBMEBMEBEBEBEBEBMEBEBMEBMMEBMEBEBEBEBMES 立法是 / 一个 / 系统 / 且 / 专业的事 / 情个人 / 认为 / 未成年人 / 保护法 / 已经过 / 时了 / 有修 / 订的 / 必要 / 否则会 / 阻碍 / 社会治 / 安工作也 / 不利于 / 保护 / 更广 / 大的 / 未成年 / 人 u"专否这个学术社交平台就是为了干翻狗屁的砖家" BEBMMEBEBEBMMEBEBMEBE 专否 / 这个学术 / 社交 / 平台 / 就是为了 / 干翻 / 狗屁的 / 砖家
关于隐马尔可夫模型用于中文分词的准确度,一是与语料相关;二是单纯使用简单的马尔科夫模型进行中文分词的准确度依然有限而不足,显得略微有些机械,确实如此;做得比较好的中文分词,一般基于了隐马尔可夫模型(HMM)但不仅仅于此,比如还可以结合最大熵模型、条件随机场、句法分析等。
用python写的源代码,写的很乱,没啥参考价值,大致看看吧:
# coding=utf-8
from get_bmes import *
import copy
import math
tmatri = { "B" : { "B": 0, "E": 0.6, "M": 0.4, "S": 0 }, \
"E" : { "B": 0.554, "E": 0, "M": 0, "S": 0.446 }, \
"M" : { "B": 0, "E": 0.716, "M": 0.284, "S": 0 }, \
"S" : { "B": 0.486, "E": 0, "M": 0, "S": 0.513 } }
for k1 in tmatri:
for k2 in tmatri[k1]:
if tmatri[k1][k2] == 0:
tmatri[k1][k2] = -9e+100
else:
tmatri[k1][k2] = math.log( tmatri[k1][k2] )
def get_bmes_value( c ):
res_dict = { "B": bmes["B"].get(c), \
"M": bmes["M"].get(c), \
"E": bmes["E"].get(c), \
"S": bmes["S"].get(c) }
for k in res_dict:
res_dict[k] = math.log( res_dict[k] )
return res_dict
# ustri 是输入的unicode类型的句子
# 根据维比特算法返回BMES类型的字符串
def get_cutting_string( ustri ):
_start = 1
res_list = []
print len(ustri)
for _i in xrange( len(ustri) ):
# 初始化
if _i == 0:
before_dict = { 'B': 0, 'M': 0, 'E': 0, 'S': 0 }
before_str = { 'B': 'B', 'M': 'M', 'E':'E', 'S':'S' }
now_dict = get_bmes_value( ustri[ _i ] )
print ustri[ _i ], now_dict
now_str = {}
res_str = ''
for k1 in now_dict:
max_p = None
for k0 in before_dict:
if _i == 0:
p = now_dict[k1] + before_dict[k0] + { 'B': -0.263, 'M': -9e+100, 'E': -9e+100, 'S': -1.465 }[k1]
else:
p = now_dict[k1] + before_dict[k0] + tmatri[ k0 ][ k1 ]
if p > max_p or not max_p:
max_p = p
res_str = before_str[k0] + k1
now_dict[k1] = max_p
now_str[k1] = res_str
print ustri[ _i ], now_dict
before_str = copy.deepcopy( now_str )
before_dict = copy.deepcopy( now_dict )
return before_str, before_dict
test_string = u"专否这个学术社交平台就是为了干翻狗屁的砖家"
# u"夷陵老祖每天都喝一杯红茶"
# u"上次我在淘宝看了几件快递员专用的大衣"
# u"立法是一个系统且专业的事情个人认为未成年人保护法已经过时了有修订的必要否则会阻碍社会治安工作也不利于保护更广大的未成年人"
# u"专否这个学术社交平台就是为了干翻狗屁的砖家"
# u"首先说一下北京同仁医院在五官科这就是鹤立鸡群的存在五官这些很重要出问题一定要去北京同仁医院北京同仁医院这么厉害建议国家多投点钱扩大一下规模和人才吧"
before_str, before_dict = get_cutting_string( test_string )
max_ppp = None
for k in before_dict:
if before_dict[k] > max_ppp or not max_ppp:
max_ppp, res = before_dict[k], before_str[k][1:]
# 边界
if res[-2] == "M" or res[-2] == "B":
res = res[:-1] + "E"
elif res[-2] == "S" or res[-2] == "E":
res = res[:-1] + "S"
print res
cool_string = u""
for i in xrange( len(res) ):
cool_string += test_string[i]
if res[i] in [ 'E', 'S' ] and i != len(res) - 1:
cool_string += " / "
print cool_string
写的比较乱,很多细节也没处理,大致看看找找感觉吧~
以上述的中文分词或者神龙吐龙珠为例,隐马尔可夫模型还可以用于语音识别、翻译、量化套利等等。
