BlackA,Talk is cheap,Show me the code.
Flask 学习笔记 #8 -- Flask-SQLAlchemy
上一节的最后我们介绍了ORM技术,接下来我们学习一个专门为 Flask 开发的ORM插件(也可以说是框架)—— Flask-SQLAlchemy。Flask-SQLAlchemy 内部封装了 SQLAlchemy(SQLAlchemy 是最流行的 Python ORM 框架之一),并化简了 SQLAlchemy 的配置和操作,使其更适合我们开发 Flask 程序。
1、安装
安装 Flask 时并不会自动安装 Flask-SQLAlchemy,所以需要我们手动安装,Flask-SQLAlchemy 的安装十分简单,只需要使如下命令:
pip install flask-sqlalchemy
如果出现以下界面说明安装成功(如果安装失败尝试使用管理员身份运行 Cmd 或在命令前加 sudo):

2、连接数据库
安装好 Flask-SQLAlchemy之后就可以使用它来操作数据库,操作数据库的第一步是连接到数据库,也就是告诉 Flask-SQLAlchemy需要操作的是哪个数据库:
from flask import Flask
# 导入 SQLAlchemy 这个类
from flask_sqlalchemy import SQLAlchemy
app = Flask(__name__)
# 添加配置信息,告诉 Flask-SQLAlchemy 需要连接到哪个数据库
app.config["SQLALCHEMY_DATABASE_URI"] = "sqlite:///mydb.db"
# 创建一个SQLAlchemy对象,连接到数据库
db = SQLAlchemy(app)
# 全部更新,这里用于测试是否成功连接到数据库
db.create_all()
@app.route('/')
def index():
return " in index"
if __name__ == "__main__":
app.run(debug=True)
我们首先从 flask_sqlalchemy这个框架中导入 SQLAlchemy这个类,然后需要添加配置信息,对 Flask-SQLAlchemy进行配置,这里直接把配置信息写入到了主脚本中(通过设置 app.config),如果要添加的配置信息比较多也可以使用第2节介绍的配置文件的方式来进行配置。
SQLALCHEMY_DATABASE_URI 是一个 Flask-SQLAlchemy允许配置的一个值,术语上讲叫做配置键。这个配置键的作用是告诉 Flask-SQLAlchemy需要连接到那个数据库,完整的配置键列表可以参考 Flask-SQLAlchemy的官方文档。
而 "sqlite:///mydb.db" 是一个连接 uri(统一资源标识符,这个和 URL 有一点点区别),它唯一的标识了要访问的是哪一个数据库,标准的连接 uri 形式如下:
dialect+driver://username:password@host:port/database
其中,dialect是数据库的实现,如 mysql、oracle、sqlite;driver指的是数据库的驱动程序,如果不指定会使用默认的驱动程序;username和password分别是访问数据库的用户名和密码,我们使用的 SQLite数据库则不需要填写;host和port表示的是主机名和端口号,我们使用的 SQLite数据库同样不需要填写;最后的 database表示数据库的路径。下面给出了一些常用的连接 uri:
- MySQL数据库:mysql://user:pass@localhost/mydatabase
- Oracle数据库:oracle://root:root@127.0.0.1:1521/sidname
- SQLite数据库:sqlite:///./mydb.db
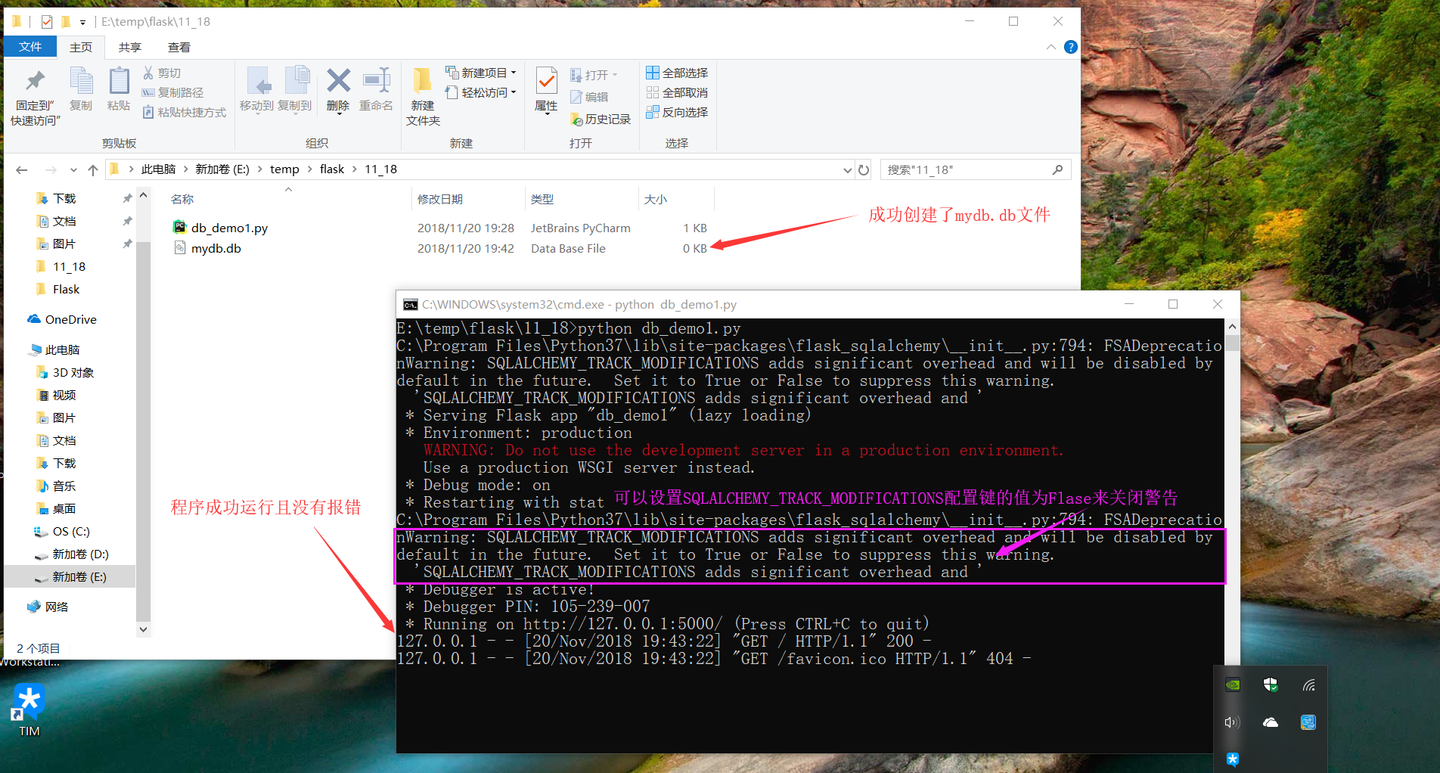
完成了配置之后我们就可以生成一个 SQLAlchemy对象来实际的连接到数据库,生成 SQLAlchemy对象时需要传入一个参数 app,表示要绑定的 Flask应用,最后通过 db.create_all() 方法应用更新。下面是这个程序的运行结果:
3、声明模型
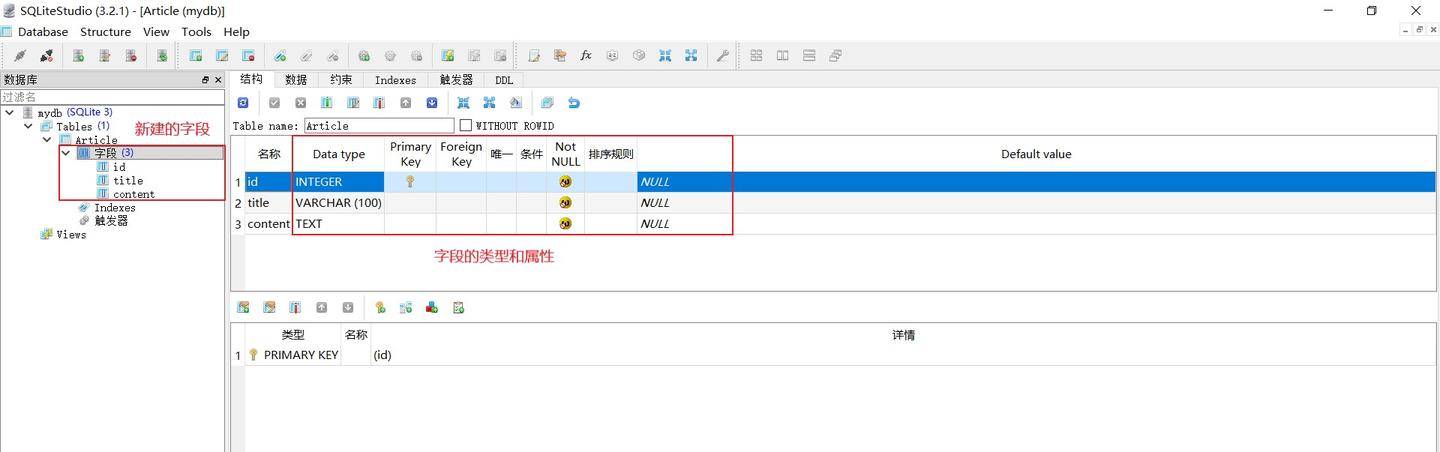
我们已经成功的使用 Flask-SQLAlchemy 连接到了数据库,接下来要做的是在创建好的数据库中新建一张表。我们同样可以使用 Flask-SQLAlchemy 来完成表的创建,具体来说就是在Flask程序中声明一个类(也可以叫模型)并建立模型与表的映射。下面的程序创建了一张具有以下结构的 Article表:

from flask import Flask
from flask_sqlalchemy import SQLAlchemy
# 连接到数据库
app = Flask(__name__)
app.config["SQLALCHEMY_DATABASE_URI"] = "sqlite:///mydb.db"
db = SQLAlchemy(app)
# 创建模型
# 模型是一个 python类,且必须继承 db.Model 父类
class Article(db.Model):
# tablename 属性定义了表名
__tablename__ = "Article"
# db.Column用来定义字段,字段名就是被赋值的变量名
# 第一个参数为字段类型,其余的关键字参数用于配置字段的属性
# primary_key表示主键,autoincrement表示自动增长
id = db.Column(db.Integer, primary_key=True, autoincrement=True)
# nullable 参数用于设置是否可以为空
title = db.Column(db.String(100), nullable=False)
content = db.Column(db.Text, nullable=False)
# db.create_all用于建立建立模型与表的映射,就是创建表
db.create_all()
@app.route('/')
def hello_world():
return 'Hello World!'
if __name__ == '__main__':
app.run()
模型必须继承且必须继承 db.Model 父类,db为前面创建的 SQLAlchemy 对象,可以通过 __tablename__ 属性定义要创建的表名,可以使用 db.Column 方法来定义一个字段,字段名就是被赋值的变量的名字,字段类型为第一个参数,下面给出了常用的字段类型:
# Integer 整数 # String(size) 字符串,size为长度 # Text 文本,长度比字符串更长 # DateTime 时间和日期 # Float 浮点数 # Boolean 布尔值 # PickleType 持久化的 Python 对象 # LargeBinary 二进制数据
db.Column 除了接受第一个参数表示类型以外,还接受一系列关键字参数表示字段的属性,下面给出了一些常用的关键字参数以及他们对应的属性(其余可参考源代码 schema.py 文件中的 Column 类):
# primary_key 设为True表示主键,多个键设为True表示复合主键 # unique 设为True表示该列不重复 # index 设为True表示创建索引,索引可以提升查询效率 # nullable 设为False表示不允许,True表示允许空值 # default 字段默认值
最后,使用 db.create_all 方法创建表,使用 db.drop_all() 删除所有的表,下面是这个程序的运行结果: